AT32F437: Эффективность работы команд Cortex-M4
Вт авг 08, 2023 21:13:56
Всем доброго времени!
Занялся переносом программ с STM32F745 на AT32F437 и наткнулся на вещи, не совместимые с документацией.... Также для меня было новостью, что если используешь кварц 25 МГц, то выстроить 288 МГц не получится. А если взять иной кварц, то не получится с CLKOUT выдать 25/50 МГц для работы ETH PHY. Печалька, но придется использовать кварц 16 МГц, разгонять до 288 МГц, а для ETH использовать свой собственный кварц или генератор.
Но дело даже не в этом.
Я вижу, что некоторые ассемблерные команды исполняются где-то за 6-7 нс, но некоторые - аж за 28-36 нс!
Что я сделал.
Я разогнал AT до 288 МГц. Проверил на таймере - действительно, это так: таймер TMR2 проходит ровно за 1 секунду 144000 такта.
Я в С описал PF10 как выход, а в asm использовал команды для быстрой SET/CLR:
; код установки бита
LDR R5, GPIO_DBG_ptr ;; GPIO_DBG_ptr содержит GPIOF_BASE + смещение регистра SCR
LDR R5, [R5] ; Грузим адрес GPIOF->SCR
MOVS R4, #DBG_SET_BSRR ; R4 <= 1<<10
STR R4, [R5] ; Сохраняем 4 команда
; код сброса бита
LDR R5, GPIO_DBG_ptr ; 5 команда
LDR R5, [R5] ; Грузим адрес GPIOF->SCR
MOVS R4, #DBG_CLR_BSRR ; R4 <= 1<<(10+16)
STR R4, [R5] ; Сохраняем 8 команда
Код разместил в FLASH, вся программа целиком (включая эти команды) влезла чуть более чем 16 кБ, загружена начиная с 0x08000000, т.е. она 100% попала в область NWS (WS=0).
Если просто запустить эти 8 команд, то при помощи осциллографа можно поймать импульс длиной аж в 70 нс!
Идем дальше. Если убрать команды 5-6, то импульс резко сокращается до 10 нс.
Опытным путем выяснил, сколько исполняются каждая из команд:
LDR R5, GPIO_DBG_ptr ; 36 нс! (это по сути команда LDR R5, [PC + 60], PC смотрит на Flash NWS (0 WS))
LDR R5, [R5] ; 24 нс!
MOVS R4, #DBG_SET_BSRR ; эта и следующая - около 10 нс.
STR R4, [R5] ;
Получается, что взять значение из периферии дольше, чем туда положить....
Может кто-нибудь в курсе, что можно сделать, чтобы нивелировать такую разницу?
Всем спасибо
Занялся переносом программ с STM32F745 на AT32F437 и наткнулся на вещи, не совместимые с документацией.... Также для меня было новостью, что если используешь кварц 25 МГц, то выстроить 288 МГц не получится. А если взять иной кварц, то не получится с CLKOUT выдать 25/50 МГц для работы ETH PHY. Печалька, но придется использовать кварц 16 МГц, разгонять до 288 МГц, а для ETH использовать свой собственный кварц или генератор.
Но дело даже не в этом.
Я вижу, что некоторые ассемблерные команды исполняются где-то за 6-7 нс, но некоторые - аж за 28-36 нс!
Что я сделал.
Я разогнал AT до 288 МГц. Проверил на таймере - действительно, это так: таймер TMR2 проходит ровно за 1 секунду 144000 такта.
Я в С описал PF10 как выход, а в asm использовал команды для быстрой SET/CLR:
; код установки бита
LDR R5, GPIO_DBG_ptr ;; GPIO_DBG_ptr содержит GPIOF_BASE + смещение регистра SCR
LDR R5, [R5] ; Грузим адрес GPIOF->SCR
MOVS R4, #DBG_SET_BSRR ; R4 <= 1<<10
STR R4, [R5] ; Сохраняем 4 команда
; код сброса бита
LDR R5, GPIO_DBG_ptr ; 5 команда
LDR R5, [R5] ; Грузим адрес GPIOF->SCR
MOVS R4, #DBG_CLR_BSRR ; R4 <= 1<<(10+16)
STR R4, [R5] ; Сохраняем 8 команда
Код разместил в FLASH, вся программа целиком (включая эти команды) влезла чуть более чем 16 кБ, загружена начиная с 0x08000000, т.е. она 100% попала в область NWS (WS=0).
Если просто запустить эти 8 команд, то при помощи осциллографа можно поймать импульс длиной аж в 70 нс!
Идем дальше. Если убрать команды 5-6, то импульс резко сокращается до 10 нс.
Опытным путем выяснил, сколько исполняются каждая из команд:
LDR R5, GPIO_DBG_ptr ; 36 нс! (это по сути команда LDR R5, [PC + 60], PC смотрит на Flash NWS (0 WS))
LDR R5, [R5] ; 24 нс!
MOVS R4, #DBG_SET_BSRR ; эта и следующая - около 10 нс.
STR R4, [R5] ;
Получается, что взять значение из периферии дольше, чем туда положить....
Может кто-нибудь в курсе, что можно сделать, чтобы нивелировать такую разницу?
Всем спасибо
Re: AT32F437: Эффективность работы команд Cortex-M4
Ср авг 09, 2023 07:00:31
Периферия работает не на частоте процессора, а на частоте шины на которой подключена. А частоты шин обычно кратно ниже.
Re: AT32F437: Эффективность работы команд Cortex-M4
Ср авг 09, 2023 21:12:30
Может кто-нибудь в курсе, что можно сделать, чтобы нивелировать такую разницу?
Для измерения времён выполнения команд следует использовать таймер DWT:
Запретив прерывания.
А вы измеряете скорость GPIO, а не команд.
Re: AT32F437: Эффективность работы команд Cortex-M4
Пт авг 11, 2023 08:19:41
А ещё есть FLASH latency, так как командам нужно время на загрузку из флеша. Плюс конвейер выполнения команд может быть загружен или нет в зависимости от предыдущих команд.
Re: AT32F437: Эффективность работы команд Cortex-M4
Сб авг 12, 2023 22:15:14
Так получилось, что основное обсуждение идёт на другом форуме (можно легко погуглить по названию темы). По итогам обсуждения сообщу результат.
Вкратце: конвейер процессора паралеллизует запросы. Если сначала загрузить в регистр, потом обрабатывать, потом его сохранять - получится долгая работа, т.к. сама по себе операция чтения долгая, и она затянется, если сразу попытаться этим регистром воспользоваться. Но это гипотеза, а правда или нет - проверю в понедельник.
Добавлено after 4 minutes 55 seconds:
У китайцев все выполняется с ws0, т.к. кэшируется в sram. И это действительно так
Вкратце: конвейер процессора паралеллизует запросы. Если сначала загрузить в регистр, потом обрабатывать, потом его сохранять - получится долгая работа, т.к. сама по себе операция чтения долгая, и она затянется, если сразу попытаться этим регистром воспользоваться. Но это гипотеза, а правда или нет - проверю в понедельник.
Добавлено after 4 minutes 55 seconds:
А ещё есть FLASH latency, так как командам нужно время на загрузку из флеша. Плюс конвейер выполнения команд может быть загружен или нет в зависимости от предыдущих команд.
У китайцев все выполняется с ws0, т.к. кэшируется в sram. И это действительно так
Re: AT32F437: Эффективность работы команд Cortex-M4
Вс авг 13, 2023 09:44:44
Вкратце: конвейер процессора паралеллизует запросы. Если сначала загрузить в регистр, потом обрабатывать, потом его сохранять - получится долгая работа
Мягко говоря, очень странное описание работы конвейера...

Вы не сможете воспользоваться содержимым регистра ни для каких целей сразу после его загрузки. Потому что "сразу" не существует.
Чтобы ускорить работу, нужно максимально использовать РОНы, а не ОЗУ общего назначения. Это таки RISC-архитектура.
Re: AT32F437: Эффективность работы команд Cortex-M4
Вт авг 15, 2023 16:41:31
Нашел ошибку у себя: задал частоту процессора вдвое меньше (144 против 288).
Но результаты исследования были очень полезны. Я поигрался с памятью, с оптимизацией и вот что получилось.
Попробовал поиграться с взятием из памяти - получилось улучшить. Пример (R0 = 0x20001A7C, R2 = 0x20001A80, R4 = 0x20001A84):
LDR R1, [R0]
ADD R1, #0
STR R1, [R0]
LDR R3, [R2]
ADD R3, #0
STR R3, [R2]
LDR R5, [R4]
ADD R5, #0
STR R5, [R4]
выполняется 49 нс (14 тактов), а последовательность
LDR R1, [R0]
LDR R3, [R2]
LDR R5, [R4]
ADD R1, #0
STR R1, [R0]
ADD R3, #0
STR R3, [R2]
ADD R5, #0
STR R5, [R4]
выполняется 42 нс (12 тактов).
(Да, я мерил своим любимым GPIO, но все сходится). В принципе, разница невелика, но есть.
Да, AT действительно работает быстрее STM. Поэтому, если речь идет об оптимизации, то лучше, если будет длительная вычислительная цепочка.
Т.е. взял значения - и долго-долго обрабатываешь, потом кладешь.
Но, если говорить о целочисленных вычислениях, то взять значения особо-то и некуда - регистров всего 12. Иное дело обстоит с регистрами FPU - их 32.
Но AT работает быстрее! Так, я запустил весь алгоритм (без оптимизации!), и получилось, что эффективность возросла где-то на 30-40 % (собственно, пропорционально тактовой частоте - 288/216 МГц).
Выводы.
1. AT на Cortex-M4 работает быстрее во всех отношениях, чем STM на Cortex-M7.
2. Оптимизация при целочисленных вычислениях не имеет смысла - мало регистров, да и процесс, как правило, один.
3. Оптимизация при "плавучных" вычислениях даст превосходный результат, т.к. есть 32 FPU регистра.
4. Если программа, требующая быстрой работы (0WS), до 512 кБ, то не надо кэшировать ее, создавать системы управления памятью - она сама грузится в SRAM и работает быстро.
5. Цена где-то в 2-3 раза ниже у китайца.
Резюме: выбираю китайца AT32F437, всё закладываю под него. Но делаю так, чтобы можно было запаять STM32F745.
Но результаты исследования были очень полезны. Я поигрался с памятью, с оптимизацией и вот что получилось.
Попробовал поиграться с взятием из памяти - получилось улучшить. Пример (R0 = 0x20001A7C, R2 = 0x20001A80, R4 = 0x20001A84):
LDR R1, [R0]
ADD R1, #0
STR R1, [R0]
LDR R3, [R2]
ADD R3, #0
STR R3, [R2]
LDR R5, [R4]
ADD R5, #0
STR R5, [R4]
выполняется 49 нс (14 тактов), а последовательность
LDR R1, [R0]
LDR R3, [R2]
LDR R5, [R4]
ADD R1, #0
STR R1, [R0]
ADD R3, #0
STR R3, [R2]
ADD R5, #0
STR R5, [R4]
выполняется 42 нс (12 тактов).
(Да, я мерил своим любимым GPIO, но все сходится). В принципе, разница невелика, но есть.
Да, AT действительно работает быстрее STM. Поэтому, если речь идет об оптимизации, то лучше, если будет длительная вычислительная цепочка.
Т.е. взял значения - и долго-долго обрабатываешь, потом кладешь.
Но, если говорить о целочисленных вычислениях, то взять значения особо-то и некуда - регистров всего 12. Иное дело обстоит с регистрами FPU - их 32.
Но AT работает быстрее! Так, я запустил весь алгоритм (без оптимизации!), и получилось, что эффективность возросла где-то на 30-40 % (собственно, пропорционально тактовой частоте - 288/216 МГц).
Выводы.
1. AT на Cortex-M4 работает быстрее во всех отношениях, чем STM на Cortex-M7.
2. Оптимизация при целочисленных вычислениях не имеет смысла - мало регистров, да и процесс, как правило, один.
3. Оптимизация при "плавучных" вычислениях даст превосходный результат, т.к. есть 32 FPU регистра.
4. Если программа, требующая быстрой работы (0WS), до 512 кБ, то не надо кэшировать ее, создавать системы управления памятью - она сама грузится в SRAM и работает быстро.
5. Цена где-то в 2-3 раза ниже у китайца.
Резюме: выбираю китайца AT32F437, всё закладываю под него. Но делаю так, чтобы можно было запаять STM32F745.
Re: AT32F437: Эффективность работы команд Cortex-M4
Ср авг 16, 2023 06:10:41
DmitryKhom писал(а):выбираю китайца AT32F437, всё закладываю под него. Но делаю так, чтобы можно было запаять STM32F745
Насколько сложно реализовать такое? Можно проиллюстрировать?
Re: AT32F437: Эффективность работы команд Cortex-M4
Вс авг 20, 2023 01:48:40
DmitryKhom писал(а):выбираю китайца AT32F437, всё закладываю под него. Но делаю так, чтобы можно было запаять STM32F745
Насколько сложно реализовать такое? Можно проиллюстрировать?
Если говорить про железо. Я использую LQFP144 в своем решении. Нашел разницу только в одном выводе №143 - это нога PDR_ON у STM32 и она же Vss у AT32. В первом случае ее мне надо к +3,3В, во втором - к GND. При том, что почти все ноги у МК задействованы в решении!
Если говорить про программу. Большинство периферии совпадает по адресам. Но RCC у STM построен иначе, чем CRM у AT; свои ограничения по частоте, нельзя построить EMAC на максимальной скорости, не прибегая к собственному генератору и т.п., у STM надо строить систему управления памятью для ускорения (использовать кэш), в то время как у AT почти вся программа туда уже грузится, и кэш с полфлэшки.
Я не задумывался об универсальной программе, которая бы сама решала, какой процессор стоит, но в принципе это возможно.
Плюс я еще не всю периферию пощупал, поэтому не все подводные камни изучил.
Re: AT32F437: Эффективность работы команд Cortex-M4
Вс авг 20, 2023 11:45:37
Перечитайте гайды по оптимизации. Это не оптимальный код для конвейера.
Что-бы небыло потерь, между использованием одного и того-же регистра должно пройти N других операций, где N = IPC.
(утрированно)
Для данного примера лучше оптимизированным будет вариант:
Смотрите исходники код других программ, в которых использовалась оптимизация.
Итак, вариант "всё загрузить" -> "всё посчитать" -> "всё сохранить" является типовым.
У себя в коде я получал IPC почти 3 (2.8, кажется) как всей работы основного цикла, для x86.
Оптимизация по взаимовлиянию регистров далеко не всё, что сказывается на потерях. Провалить скорость можно по массе причин - не граннулярно выбрано кеширование, размещение в памяти (по странцам 4к), использование неудачных инструкций (почему удалили всеми любимый оператор INC) и т.д. Компилятор об этом знает и может правильно оптимизировать код, а "руками" ... неа, жалкие потуги.
Что до ARM'а, то его optimization guide не читал и не нужен мне этот кошмар на ночь. ))
Что-бы небыло потерь, между использованием одного и того-же регистра должно пройти N других операций, где N = IPC.
(утрированно)
Для данного примера лучше оптимизированным будет вариант:
- Код:
LDR R1, [R0]
LDR R3, [R2]
LDR R5, [R4]
ADD R1, #0
ADD R3, #0
ADD R5, #0
STR R1, [R0]
STR R3, [R2]
STR R5, [R4]
Смотрите исходники код других программ, в которых использовалась оптимизация.
Итак, вариант "всё загрузить" -> "всё посчитать" -> "всё сохранить" является типовым.
У себя в коде я получал IPC почти 3 (2.8, кажется) как всей работы основного цикла, для x86.
Оптимизация по взаимовлиянию регистров далеко не всё, что сказывается на потерях. Провалить скорость можно по массе причин - не граннулярно выбрано кеширование, размещение в памяти (по странцам 4к), использование неудачных инструкций (почему удалили всеми любимый оператор INC) и т.д. Компилятор об этом знает и может правильно оптимизировать код, а "руками" ... неа, жалкие потуги.
Что до ARM'а, то его optimization guide не читал и не нужен мне этот кошмар на ночь. ))
Re: AT32F437: Эффективность работы команд Cortex-M4
Ср авг 23, 2023 13:35:44
u37 писал(а):для x86.
u37 писал(а):Что до ARM'а, то его optimization guide не читал
И вот так запросто сравнивать CISC и RISC, да ещё и большую машину с микроконтроллером? Смело!
Re: AT32F437: Эффективность работы команд Cortex-M4
Пт авг 25, 2023 17:42:30
Перечитайте гайды по оптимизации. Это не оптимальный код для конвейера.
Бред.В Cortex-M4 нет никаких конвееров.
Что до ARM'а, то его optimization guide не читал и не нужен мне этот кошмар на ночь. ))
К хирургу вы тоже приходите с фразой: "Этих ваших гайдов по хирургии я не читал, но резать нужно так..." ? Re: AT32F437: Эффективность работы команд Cortex-M4
Пт авг 25, 2023 21:00:28
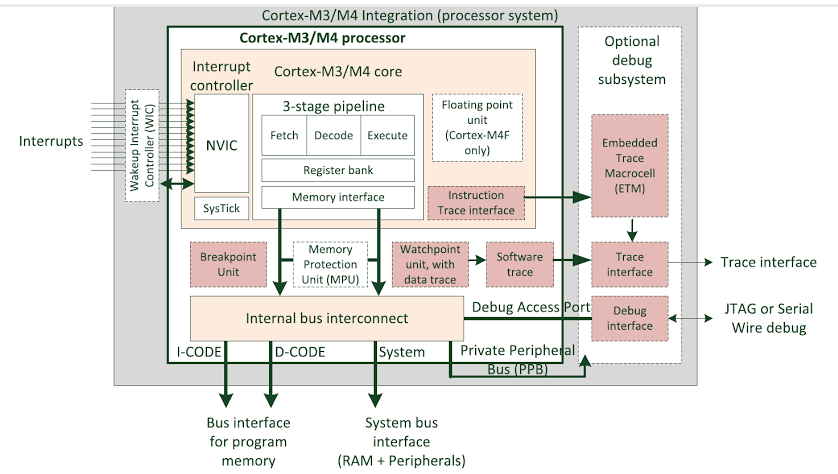
Re: AT32F437: Эффективность работы команд Cortex-M4
Сб авг 26, 2023 00:37:50
Вообще то есть.
3-stage pipeline.
Это вообще не о том. Нету там конвеера того типа, о котором вещает u37. В CM4 нет никакой разницы в скорости, исполняются ли LDR/ADD/STR друг за другом или перемешаны с другими командами (за исключением идущих подряд LDR с определёнными типами адресаций).3-stage pipeline.
Т.е. - использование слова, загруженного LDR сразу же в следующей команде ADD, никак само по себе не штрафуется (дополнительными тактами). В любом случае ADD будет = 1 такт. Как и сохранение результата сразу после ADD - тоже никак не штрафуется.