Целочисленное преобразование Фурье большого порядка
Пт мар 17, 2023 19:37:21
Есть задача на процессорах ARM вычислять БПФ больших порядков (до 2^20). Работа с double медленна, потому хочется в целых числах. Я написал реализацию, которая работает нормально примерно до порядка 12. Потом (на порядках выше) все тонет в шумах. На просторах интернета тоже видел целочисленные реализации, но они тоже касаются маленьких порядков типа 2^8 или 2^10.
Re: Целочисленное преобразование Фурье большого порядка
Пт мар 17, 2023 20:10:37
Я тоже пытался на мегометре , сделать расчёты ... но что бы было точно , нужно было 500 000 000 000 разделить на что то ... И размер памяти аттини 26 кончился .
Re: Целочисленное преобразование Фурье большого порядка
Сб мар 18, 2023 07:52:39
Есть задача
А в даблах, пусть и медленно, в шумах не тонет?
И откуда взят сигнал для фильтрации? Каким АЦП получены исходные данные? Какая длина массива?
Ну и зачем нужен 20-разрядный инт, если флоат имеет 23 разряда мантиссы и он аппаратно поддержан АРМами в которых имеется FPU? Причем тут вообще дабл?
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 12:17:07
Используйте SIMD инструкции, они резко ускоряют обработку.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 13:36:47
SIMD инструкции
Это если NEON поддерживается целевым чипом. Что не факт. Я даже не уверен, что речь идет о процессоре. Скорее всего о контроллере. Насколько мне известно, NEON поддерживается, только начиная с Cortex-A.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 13:50:46
КРАМ, M4-f точно умеет, но не НЕОН, конечно. А вот что за числодробилка смотрите в следующей серии!
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 14:09:48
КРАМ, M4-f точно умеет, но не НЕОН
Вы упомянули конкретно SIMD. В ARM-ах SIMD - это NEON. В M4F NEON-а нет. А значит нет и SIMD.
Тогда о чем идет речь?

Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 15:01:19
КРАМ писал(а):Вы упомянули конкретно SIMD.
Single instruction, multi data. Одной командой перемножить две пары чисел и всё в таком духе.
КРАМ писал(а):В ARM-ах SIMD - это NEON
Насколько я понимаю, НЕОН это название одно из наборов инструкций. АРМов же всяких существует уйма. Вот, например, картинка про кортексы М. Моя любимая инструкция SMLALD. Это знаковое перемножение двух пар чисел 16 бит, сложение результатов между собой и сложение с аккумулятором 64 бита. Целый день на работе ей пользуюсь!
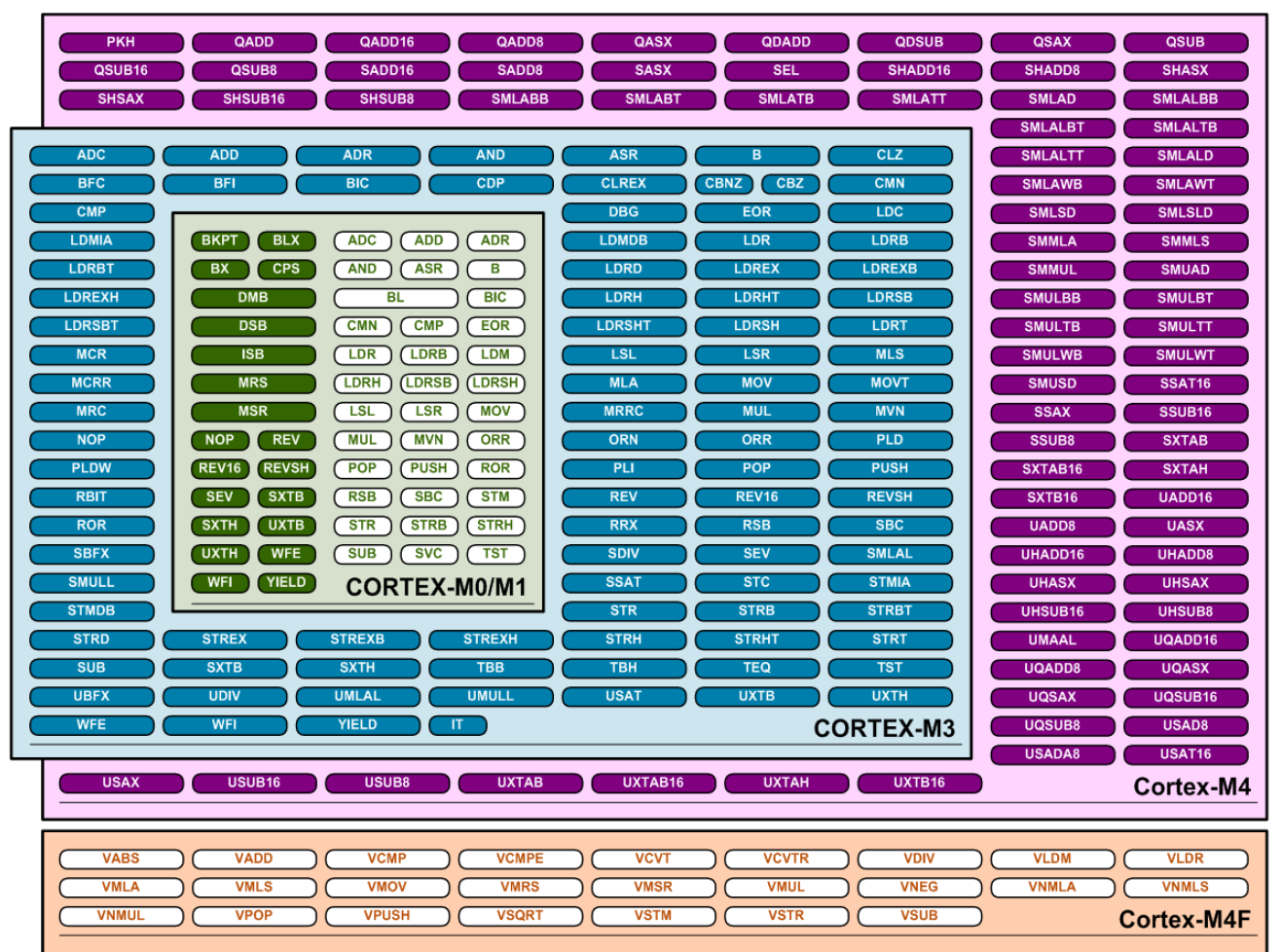
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 15:17:38
Моя любимая инструкция SMLALD.
И причем тут SIMD?
Обычная инструкция из набора DSP. Причем это даже не trueDSP. Попытка догнать настоящую MAC-инструкцию.
Дело в том, что все DSP инструкции ARM-ов работают только с регистрами ядра. Загрузка регистров ядра и расчет текущих указателей для загрузки регистров для MAC делаются отдельно.
Например, в DSP-ядре Микрочипа (dsPIC33) ОЗУ разделено на две области X и Y, что дает возможность В ОДНОМ МАШИННОМ ЦИКЛЕ производить загрузку сразу двух операндов для MAC-инструкций. Итого за один машцикл делается умножение двух РОНов, сложение с результата с аккумулятором, загрузка двух РОНов по РОНам-указателям из ОЗУ и модификация (инкремент/декремент с заданным шагом) РОНов-указателей, а так же выгрузка аккумулятора в РОН с округлением (опционально)
Итого 7 простых инструкций за 1 машинный цикл.
Работать с памятью в двухканальном режиме обычный Кортекс-М не умеет. Ему не позволяет архитектура.
ЗЫ. В догон. И все это не SIMD, а WLIV, есличо...
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 15:37:56
"VLIW (англ. very long instruction word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами."
RISC с одним АЛУ это VLIW? Как минимум один из нас запутался в понятиях.
Добавлено after 1 minute 26 seconds:
Так я же именно это и описал. Не понимаю о чём спорим.
RISC с одним АЛУ это VLIW? Как минимум один из нас запутался в понятиях.
Добавлено after 1 minute 26 seconds:
КРАМ писал(а):SIMD- это другое.
Так я же именно это и описал. Не понимаю о чём спорим.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 15:48:06
Как минимум один из нас запутался в понятиях.
И это не я...
Вы пытаетесь извлечь смысл ТОЛЬКО из названия. В этом и проблема.
WLIV - это когда ОДНА инструкция содержит несколько инструкций.
SIMD - это когда ОДНА инструкция выполняется сразу несколькими вычислителями.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 16:02:10
КРАМ писал(а):И это не я...
И не я
КРАМ писал(а):WLIV - это когда ОДНА инструкция содержит несколько инструкций.
SIMD - это когда ОДНА инструкция выполняется сразу несколькими вычислителями.
Так наоборот же. Вот, по вашей же ссылке: "VLIW (англ. very long instruction word — «очень длинная машинная команда») — архитектура процессоров с несколькими вычислительными устройствами.".
Короче ладно, не в драку же теперь лезть в самом деле
 . Как хотя бы подель процессора узнаем можно уже будет что-то определённое говорить.
. Как хотя бы подель процессора узнаем можно уже будет что-то определённое говорить.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 16:24:55
Так наоборот же.
НЕТ!!!
Предлагаю вам прочесть не только расшифровку аббревиатуры, но и что нибудь по существу.
Под длинной командой понимается НЕСКОЛЬКО ИНСТРУКЦИЙ в одной. Она потому и длинная.
А SIMD - это КОРОТКАЯ ИНСТРУКЦИЯ выполняемая ОДНОВРЕМЕННО И ИДЕНТИЧНО над несколькими ГРУППАМИ операндов. Например одновременно делается 8 одинаковых умножений над восемью парами РОНов.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 16:45:26
Ну да, в кортексе м SMLALD как раз из коротких. В одном регистре одна группа операндов, в другом регистре другая группа. Эти группы одновременно и идентично попарно перемножаются, а потом в этом же машинном цикле прибавляются все вместе к аккумулятору. Вроде всё так . Из памяти в регистры надо значения достать заранее. А ещё в некоторых СТМах встречал CCM. Фактически кусок оперативы со своей дополнительной шиной. Но таки параллельной выборки данных не припомню. С натяжкой даже можно сказать, что из-за этого можно извращнуться и скакать между Фон Неймановской архитектурой и Гарвардской. Ну типа то одна шина инструкций-данных, то разные. Хотя функционально они равноправны, ибо код из CCM неплохо так выполняется. Но это уже совсем дебри, словоблудие и онанизм.
. Из памяти в регистры надо значения достать заранее. А ещё в некоторых СТМах встречал CCM. Фактически кусок оперативы со своей дополнительной шиной. Но таки параллельной выборки данных не припомню. С натяжкой даже можно сказать, что из-за этого можно извращнуться и скакать между Фон Неймановской архитектурой и Гарвардской. Ну типа то одна шина инструкций-данных, то разные. Хотя функционально они равноправны, ибо код из CCM неплохо так выполняется. Но это уже совсем дебри, словоблудие и онанизм.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 16:54:21
Вроде всё так . Из памяти в регистры надо значения достать заранее.
. Из памяти в регистры надо значения достать заранее.Называть SIMD всего две группы как то некуртуазно и нескромно. Тем более, что потом еще и суммируется аккумулятор, что уже явно не SIMD. Тут наблюдается очевидная эклектика.
Основные траты времени при построении фильтров и преобразовании Фурье возникают как раз на загрузку операндов и модификацию указателей. Экономить одно умножение - это ни о чём...
Обсуждаемая инструкция АРМа практически никак не изменит производительность при расчете "бабочки" БПФ. Да и в ДПФ она мало чем поможет.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 17:00:26
Согласен, операции с памятью самые ресурсозатратные. Однако даже и тут есть ощутимый выигрыш. Вместо загрузки двух разных значений по 16 бит загружается одно на 32 бита. За один раз. И сохраняется так же.
Re: Целочисленное преобразование Фурье большого порядка
Ср мар 22, 2023 17:11:34
Но таки параллельной выборки данных не припомню.
ВОООТ! Ибо это противоречит идеологии RISC-процессора.
Приведу пример суперэффективного кода КИХ ФНЧ (FIR) для dsPIC33:
- Код:
repeat #511
mac W4*W5, A, [W8]+=2, W4, [W10]+=2, W5
То есть фильтр (до нормирования) считается тупо как повтор единственной инструкции 512 раз.
Добавлено after 5 minutes 24 seconds:
Вместо загрузки двух разных значений по 16 бит загружается одно на 32 бита. За один раз.
Остается вопрос - ЗАЧЕМ?
Дело в том. что при выполнении MAC-инструкций (той самой, о которой идет речь для АРМа) одним из умножаемых операндов является ОТСЧЕТ из массива входных данных, а второй - это КОЭФФИЦИЕНТ ФИЛЬТРА. Это совершенно разные массивы. И как их загрузить вместе? Мало этого, шаг загрузки может быть не равен шагу в памяти...

Re: Целочисленное преобразование Фурье большого порядка
Пт мар 24, 2023 14:00:28
Вдруг кому будет полезно. У меня получилось БПФ любого порядка на целых числах. Причем на int64 вообще легко, на int32 надо иногда за приближением к границе разрядной сетки смотреть, а на int16 просто постоянно делить на 2 на каждой внешней итерации БПФ, запоминая суммарную нормировку. Но интерес не в этом.
Существенного прироста по сравнению с float (да и с double) я не достиг. int64 примерно в 1.5 раза медленнее, чем float. int32 почти так же, как и float. int16 примерно на 10% быстрее, чем float. В общем, ожидал получить существенно больший прирост. SIMD (NEON) пока еще не использовал, но даже без SIMD получилось быстрее, чем все библиотеки БПФ, которые удалось нарыть в интернете и которые используют Neon.
А прироста в целочисленных вычислениях я ждал, потому что когда на этом же процессоре (а у меня Cortex A-9) и при этих же ключах компиляции перешел с float на int16 на задаче вычисления свертки, получил выигрыш примерно в 8 раз. Кто-то может пояснить сей парадокс?
Существенного прироста по сравнению с float (да и с double) я не достиг. int64 примерно в 1.5 раза медленнее, чем float. int32 почти так же, как и float. int16 примерно на 10% быстрее, чем float. В общем, ожидал получить существенно больший прирост. SIMD (NEON) пока еще не использовал, но даже без SIMD получилось быстрее, чем все библиотеки БПФ, которые удалось нарыть в интернете и которые используют Neon.
А прироста в целочисленных вычислениях я ждал, потому что когда на этом же процессоре (а у меня Cortex A-9) и при этих же ключах компиляции перешел с float на int16 на задаче вычисления свертки, получил выигрыш примерно в 8 раз. Кто-то может пояснить сей парадокс?
Re: Целочисленное преобразование Фурье большого порядка
Пт мар 24, 2023 15:07:00
Кто-то может пояснить сей парадокс?
Проблема в том, что БПФ это не совсем свертка. Проблема БПФ в том, что основное время уходит не на MAC, а на бесконечные перезагрузки РОНов, которые в этой архитектуре не могут происходить одновременно с MAC.
Выигрыш в ДПФ будет гораздо заметнее, поскольку там вычисления имеют регулярный характер.
В качестве примера нерегулярности вычислений приведу АСМ код "бабочки" БПФ для dsPIC33, который может работать как VLIW:
- Код:
; W10=pA
; W11=pB
; W8=pW
; A=A+B
; B=(A-B)W
BtflCmplx:
mov #0x7FFF, W4 ; W4=0.99999
clr A, [W10]+=2, W6 ; W6=Ar, [W10]->Ai
clr B, [W8]+=2, W5, [W11]+=2, W7 ; W7=Br, [W11]->Bi, W5=Wr [W8]->Wi
;--- perform A
mac W4*W6, A, [W10]-=2, W6 ; ACCA=+(1*Ar), W6=Ai, [W10]->Ar
mac W4*W7, A, [W11]-=2, W7 ; ACCA=+(1*Br), W7=Bi, [W11]->Br
sac.r A, #-1, [W13++] ; Ar(new)=ACCA.rnd->buf
mac W4*W6, B, [W10]+=2, W6 ; ACCB=+(1*Ai), W6=Ar, [W10]->Ai
mac W4*W7, B, [W11]+=2, W7 ; ACCB=+(1*Bi), W7=Br, [W11]->Bi
sac.r B, #-1, [W13++] ; Ai(new)=ACCB.rnd->buf
;--- perform B
mpy W5*W6, A, [W10]-=2, W6 ; ACCA=Wr*Ar, W6=Ai, [W10]->Ar
msc W5*W7, A, [W8]-=2, W5, [W11]-=2, W7 ; ACCA=-(Wr*Br), W5=Wi, [W8]->Wr, W7=Bi, [W11]->Br
msc W5*W6, A ; ACCA=-(Wi*Ai)
mac W5*W7, A, [W8]+=2, W5 ; ACCA=+(Wi*Bi), W5=Wr, [W8]->Wi
sac.r A, #-1, [W13++] ; Br(new)=ACCA.rnd->buf
mpy W5*W6, B, [W10]+=2, W6 ; ACCB=Wr*Ai, W6=Ar, [W10]->Ai
msc W5*W7, B, [W8], W5, [W11]+=2, W7 ; ACCB=-(Wr*Bi), W5=Wi, W7=Br, [W11]->Bi
mac W5*W6, B ; ACCB=+(Wi*Ar)
msc W5*W7, B ; ACCB=-(Wi*Br)
sac.r B, #-1, [W13] ; Bi(new)=ACCB.rnd->buf
mov [W13--], [W11--] ; save Bi
mov [W13--], [W11] ; save Br
mov [W13--], [W10--] ; save Ai
mov [W13], [W10] ; save Ar
return
Re: Целочисленное преобразование Фурье большого порядка
Пт мар 24, 2023 16:06:49
Проблема в том, что БПФ это не совсем свертка. Проблема БПФ в том, что основное время уходит не на MAC, а на бесконечные перезагрузки РОНов, которые в этой архитектуре не могут происходить одновременно с MAC.
Можете немного пояснить для тех, кто под arm программирует одну неделю, что такое MAC и РОН. Или ссылку почитать.
Выигрыш в ДПФ будет гораздо заметнее, поскольку там вычисления имеют регулярный характер.
Наверное, вы хотели написать "Выигрыш в свертке будет гораздо заметнее"