Немного про оптимизацию
Сб янв 29, 2022 11:25:24
Подсмотрел тут на досуге листинг простейшего кусочка кода - дернуть ножкой.
Так вот, в первом случае от брика до брика 9 тактов, а во втором 7.
- Код:
PA1::set();
PA1::clear();
- Код:
// Без оптимизации Instruction Scheduling
BKPT #0x0
LDR.N R1,??DataTable1_1
MOVS R0,#+2
STR R0,[R1, #+4]
STRH R0,[R1, #+6]
BKPT #0x0
- Код:
// С оптимизацией Instruction Scheduling
BKPT #0x0
MOVS R0,#+2
LDR.N R1,??DataTable1_1
STR R0,[R1, #+4]
MOVS R2,#+2
STRH R2,[R1, #+6]
BKPT #0x0
Так вот, в первом случае от брика до брика 9 тактов, а во втором 7.
Re: Немного про оптимизацию
Пн фев 14, 2022 18:37:15
Ядро Cortex-M4, выполнение из SRAM. Обернул двумя брикпоинтами и замерил скорость выполнения по DWT_CYCCNT.
У меня часто закрадываются сомнения в адекватности показаний DWT_CYCCNT при измерении малых участков кода. Например на моём CM4F IAR мне упорно показывает длительность выполнения одной инструкции UMULL = 4 такта! Хотя вроде должно быть = 1.Надёжней: зациклить и проверить длительность многократного выполнения. С запрещёнными прерываниями. С последующим делением и вычитанием затрат на организацию цикла.
Re: Немного про оптимизацию
Пн фев 28, 2022 18:06:09
Подсмотрел тут на досуге листинг простейшего кусочка кода - дернуть ножкой.
...
Так вот, в первом случае от брика до брика 9 тактов, а во втором 7.
...
Так вот, в первом случае от брика до брика 9 тактов, а во втором 7.
А в чём проблема? В первом случае выполнение STRH останавливается, так как буфер записи вмещает лишь одно значение, и до фактичекского завершения STR новая операция записи не может быть начата. Во втором случае между ними есть промежуток, поэтому проц не останавливается.
Re: Немного про оптимизацию
Пн фев 28, 2022 18:19:11
Проблемы никакой нет. Есть вопрос какой код выполнится быстрее?
Re: Немного про оптимизацию
Вт мар 01, 2022 22:01:55
VladislavS, IAR запуск отладки из RAM, stm32f100rb
Что здесь не так?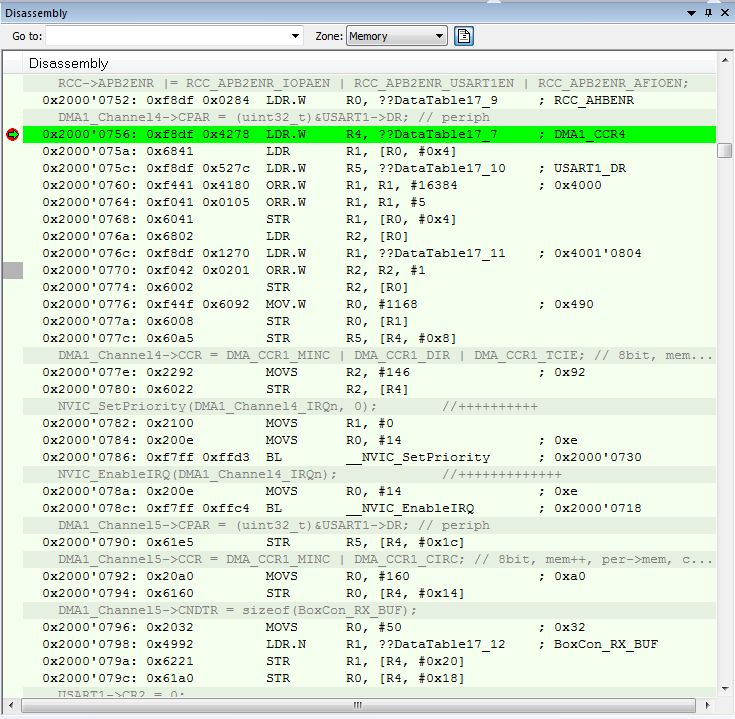
Не хочет писать в CPAR регистр
Ручками скопируешь из DMA1_Channel5->CPAR в DMA1_Channel4->CPAR, работает.
Что здесь не так?
Спойлер
Не хочет писать в CPAR регистр
- Код:
DMA1_Channel4->CPAR = (uint32_t)&USART1->DR;
- Код:
DMA1_Channel5->CPAR = (uint32_t)&USART1->DR;
Ручками скопируешь из DMA1_Channel5->CPAR в DMA1_Channel4->CPAR, работает.
Re: Немного про оптимизацию
Ср мар 02, 2022 21:10:58
Пока вышел из положения вот таким способом
Спойлер
- Код:
DMA1_Channel4->CPAR = 0;
DMA1_Channel4->CPAR = (uint32_t)&USART1->DR;
DMA1_Channel4->CCR = DMA_CCR1_MINC | DMA_CCR1_DIR | DMA_CCR1_TCIE;
NVIC_SetPriority(DMA1_Channel4_IRQn, 0);
NVIC_EnableIRQ(DMA1_Channel4_IRQn);
DMA1_Channel5->CPAR = (uint32_t)&USART1->DR;
DMA1_Channel5->CCR = DMA_CCR1_MINC | DMA_CCR1_CIRC;